vanna.ai
tags :
Python Apps AI #
 Using prior SQL queries that worked to improve the results
Using prior SQL queries that worked to improve the results
Why Vanna.AI? #

Supported Databases #
Supported Vector Stores or Metadata Store
- Vanna hosted vectordb
- Marqo
Other Vector Stores
%pip install 'vanna[openai,mysql]' from vanna.openai import OpenAI_Chat from vanna.base import VannaBase class MyCustomVectorDB(VannaBase): def add_ddl(self, ddl: str, **kwargs) -> str: # Implement here def add_documentation(self, doc: str, **kwargs) -> str: # Implement here def add_question_sql(self, question: str, sql: str, **kwargs) -> str: # Implement here def get_related_ddl(self, question: str, **kwargs) -> list: # Implement here def get_related_documentation(self, question: str, **kwargs) -> list: # Implement here def get_similar_question_sql(self, question: str, **kwargs) -> list: # Implement here def get_training_data(self, **kwargs) -> pd.DataFrame: # Implement here def remove_training_data(id: str, **kwargs) -> bool: # Implement here class MyVanna(MyCustomVectorDB, OpenAI_Chat): def __init__(self, config=None): MyCustomVectorDB.__init__(self, config=config) OpenAI_Chat.__init__(self, config=config) vn = MyVanna(config='api_key': 'sk-...', 'model': 'gpt-4-...')- TODO try implementing this with OpenSearch
OCR of Images #
2024-05-12_13-43-20_screenshot.png #
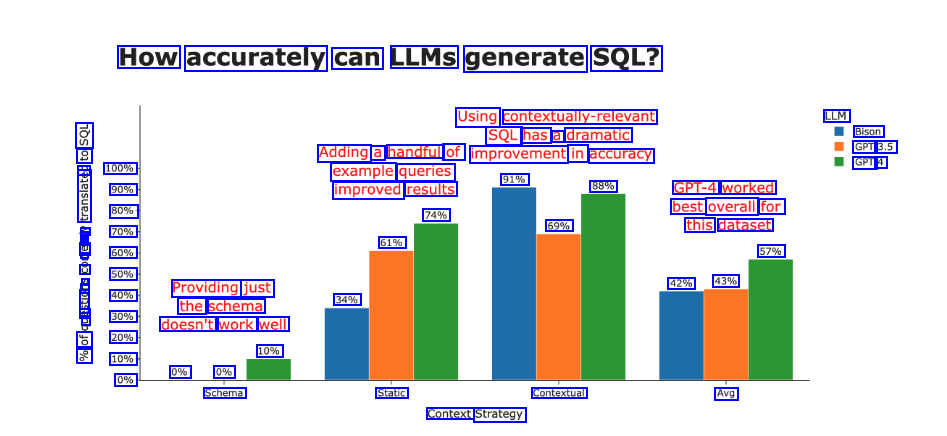
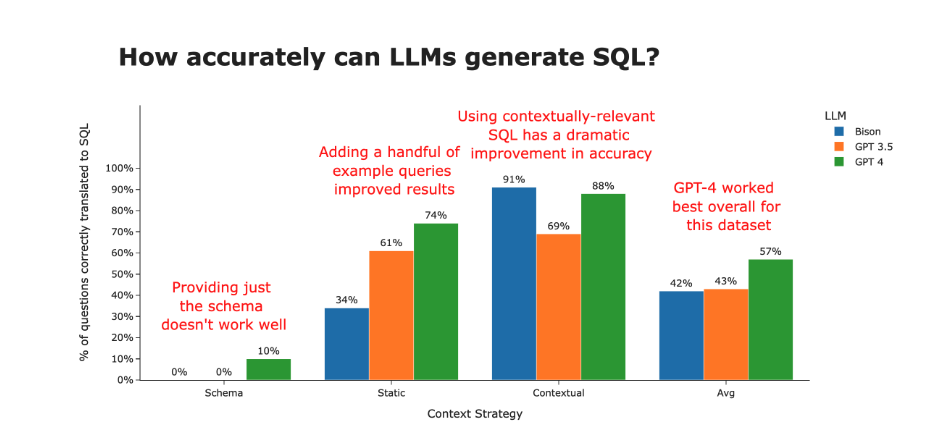
How accurately can LLMS generate SQL? Using contextually-relevant SQL has a dramatic LLM Bison GPT 3.5 GPT 4 8 e DE 100% 90% 80%- I A 70% L - a a - 60% U 50% a E 8 40% a 3 30% of 20% e 10% Adding a handful of improvement in accuracy example queries improved results 91% 88% GPT-4 worked best overall for this dataset 74% 69% 61% 57% 42% 43% Providing just the schema doesn't work well 34% 10% 0% 0% Schema 0% Static Contextual Avg Context Strategy
2024-05-12_13-44-35_screenshot.png #
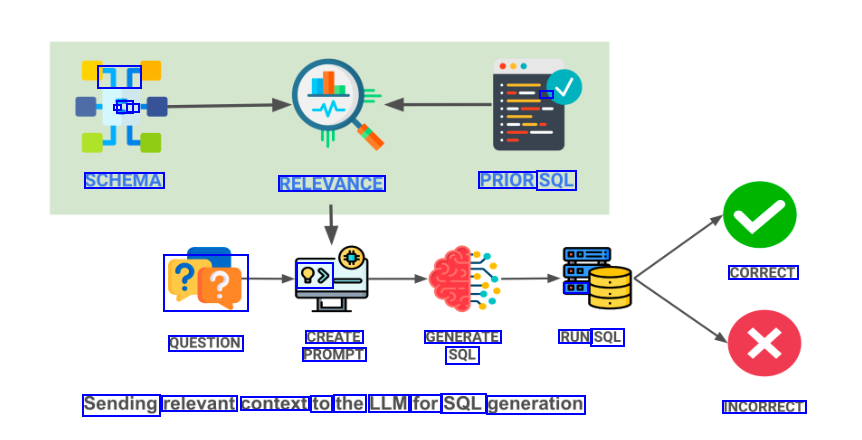
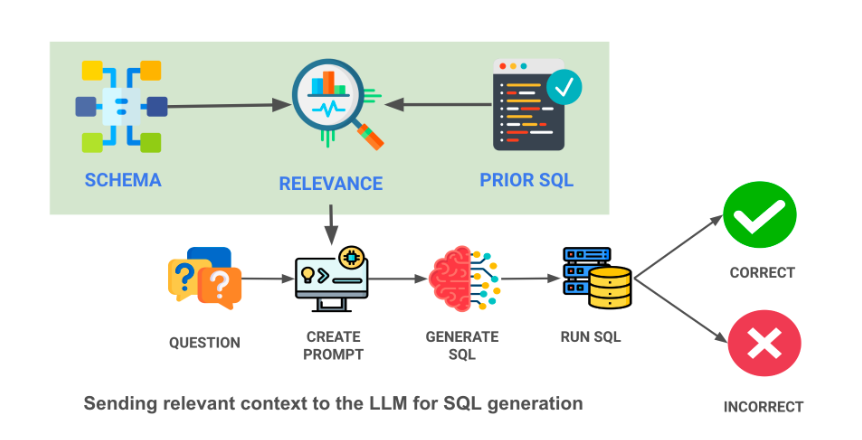
r - - - - SCHEMA RELEVANCE PRIOR SQL 99 CORRECT ?1?) 00 QUESTION CREATE PROMPT GENERATE SQL RUN SQL Sending relevant context to the LLM for SQL generation INCORRECT
2024-05-12_13-45-39_screenshot.png #

Why Vanna.Al? D Open-Source High accuracy on complex datasets Vanna's capabilities are tied to the training data you give it. More training data means better accuracy for large and complex datasets. Designed for security The Vanna Python package and the various frontend integrations are all open-source. You can run Vanna on your own infrastructure. Your database contents are never sent to the LLM unless you specifically enable features that require it. The metadata storage layer only sees schemas, documentation, and queries. Self learning Supports many databases Choose your front end As you use Vanna more, your model continuously improves as' we augment your training data. We have out-of-the-box support Snowflake BigQuery, Postgres, and many others. You can easily make a connector for any database. Start in a Jupyter Notebook. Expose to business users via Slackbot, web app, Streamlit app, any other frontend. Even integrate in your web app for customers.