Tokenizer
tags :
Summary #
From OpenAI #
ref The family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens.
Elasticsearch #
a process of splitting text content into individual words by inserting a whitespace delimiter, a letter, a pattern, or other criteria. This process is carried out by a component called a tokenizer, whose sole job is to chop the content into individual words called tokens by following certain rules when breaking the content into words.
OCR of Images #
2023-08-26_09-15-14_screenshot.png #
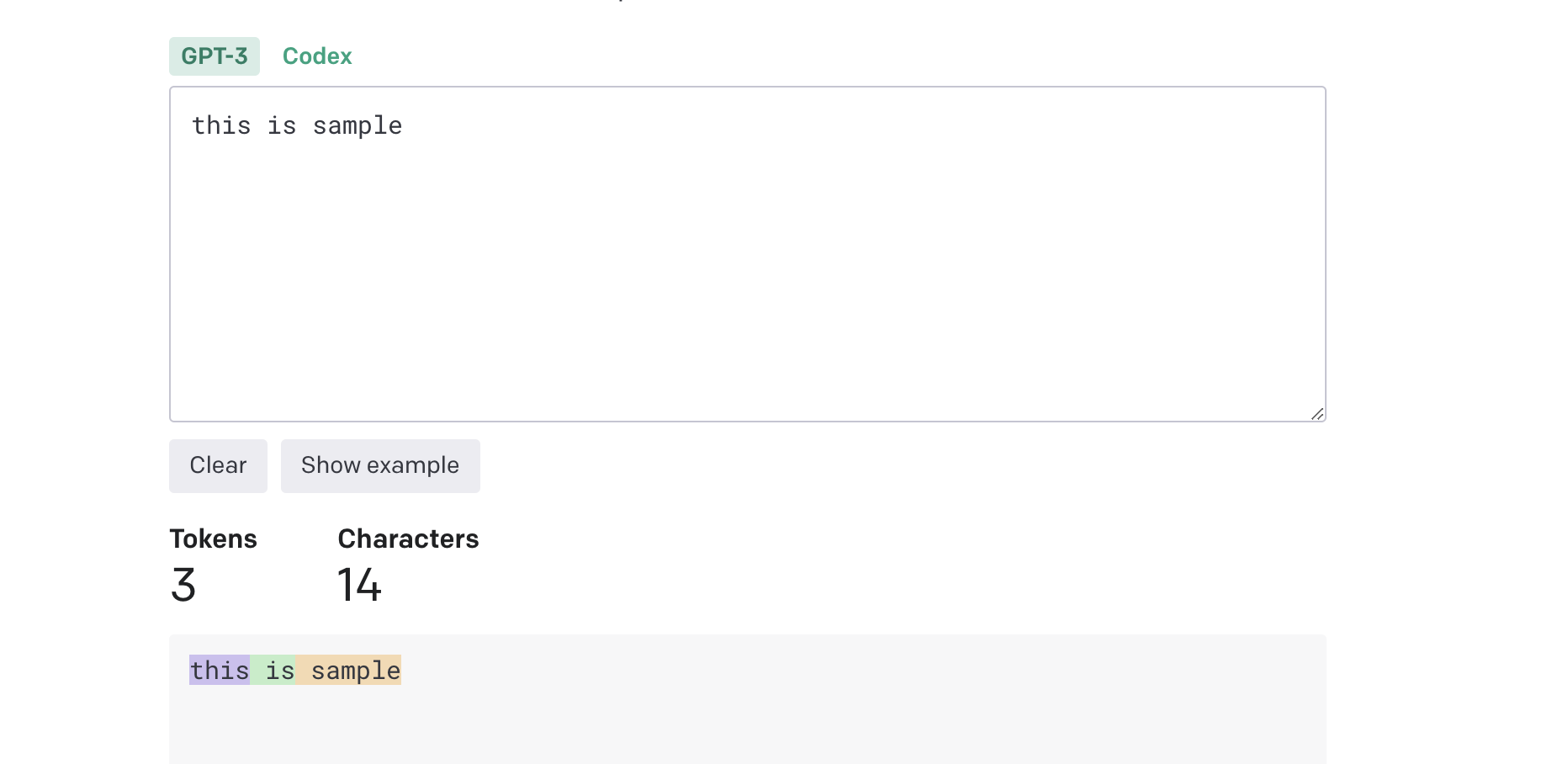
GPT-3 Codex this is sample l Clear Show example Tokens 3 Characters 14 this is sample
2023-08-26_09-20-36_screenshot.png #
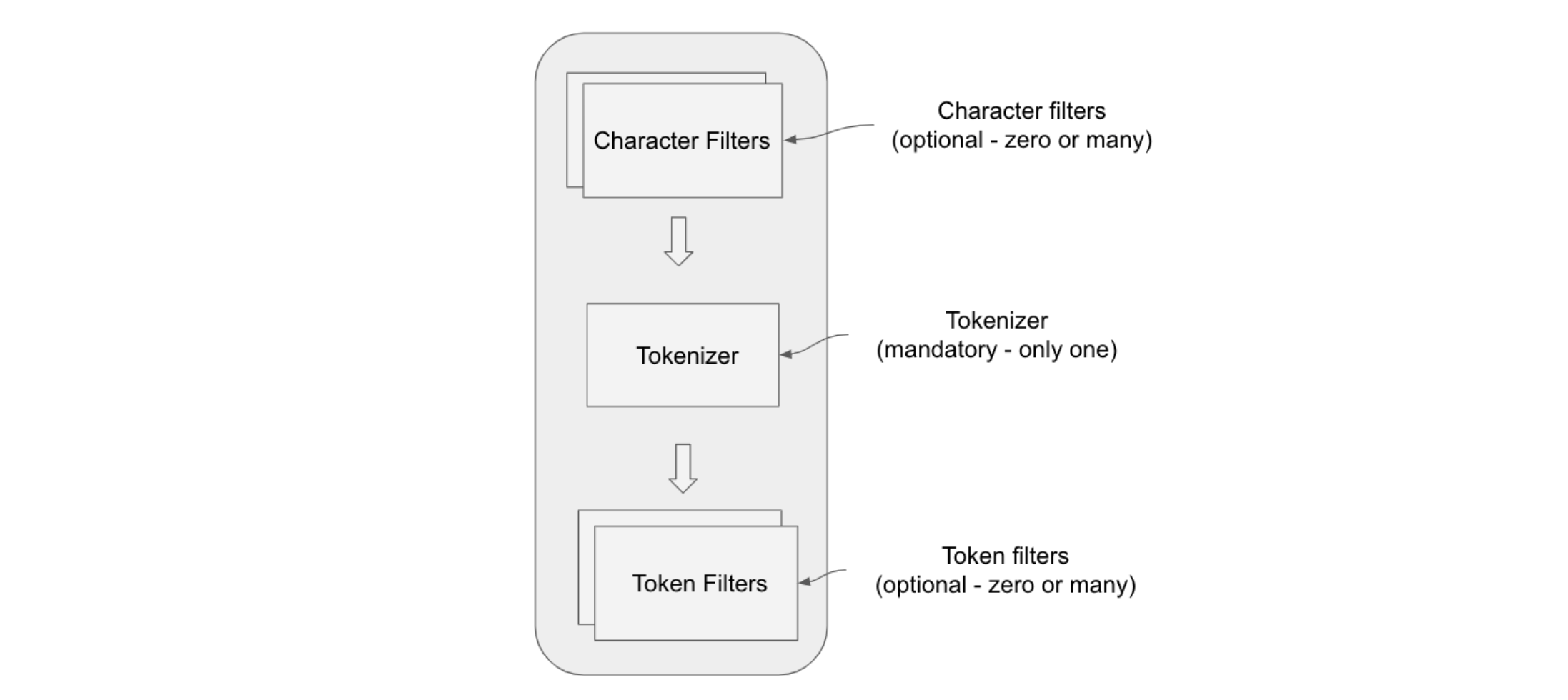
Character filters (optional - zero or many) Character Filters Tokenizer (mandatory - only one) Tokenizer Token filters (optional - zero or many) Token Filters