Sparse Encoding
- tags
- OpenSearch
Sparse Encoding #
- Sparse encoding models (Embedding)
transfer text into a sparse vector and convert the vector to a list of <token: weight> pairs representing the text entry and its corresponding weight in the sparse vector. - You can use these models for Use Cases such as clustering or sparse neural search.
Example #
Here’s a simple example to understand sparse encoding:
Text: “The cat sat on the mat”
Sparse encoding might convert this into token-weight pairs like:
[
(cat: 0.6),
(sat: 0.4),
(mat: 0.5),
(the: 0.1)
]
Notice:
- Common words (“the”) get lower weights
- Content words (“cat”, “mat”) get higher weights
- Many possible tokens are 0 and omitted
- Only meaningful tokens with non-zero weights are stored
This is “sparse” because most potential tokens have zero weight and are excluded, making it memory-efficient.
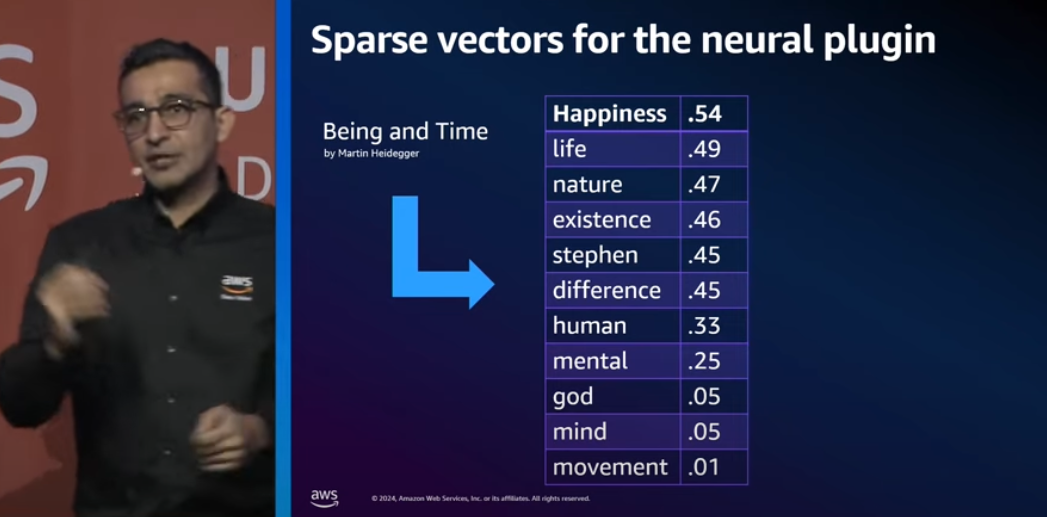
To a document while indexing it is like adding more related to words to increase the chances of its getting found
adding more related to the query and the document to increase the chances of better match with sparse encoding.


Overlap
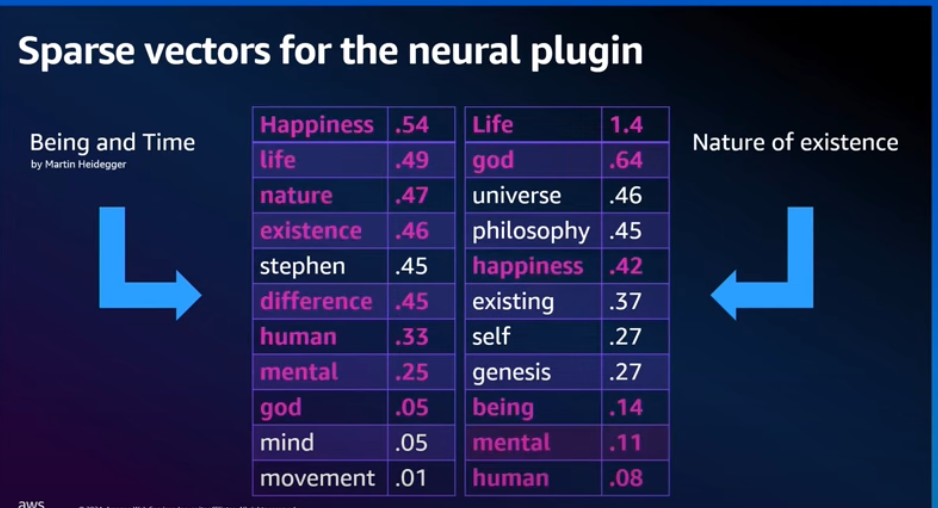

- Improvement is over both BM25 and Dense vector search
Sparse Encoding vs Dense Encoding #
Sparse encoding and dense encoding are two different approaches to text representation with distinct characteristics and use cases:
Sparse Encoding #
- Structure: Represents text as high-dimensional vectors where most dimensions are zero.
- Interpretability: Each dimension corresponds to a specific token, making it easy to interpret.
- Efficiency: Efficient for matching and querying due to sparsity; only non-zero values are stored and processed.
- Example Use Cases: Information retrieval, search engines, clustering, where interpretability and matching based on explicit token presence are important.
Dense Encoding #
- Structure: Converts text into lower-dimensional, dense vectors where every dimension typically has a non-zero value.
- Interpretability: Often lacks direct interpretability as dimensions do not correspond to specific tokens.
- Efficiency: Can capture complex semantic meanings and relationships between words, effective for deep learning and similarity search.
- Example Use Cases: Semantic Search, sentiment analysis, natural language processing tasks where understanding nuanced meanings is beneficial.
Comparison #
- Sparse encoding is favored when you need a straightforward representation that explicitly captures token presence and absence, such as in certain search applications.
- Dense encoding is preferable when you require understanding of semantic contexts and subtleties in language, which can be beneficial in more advanced AI tasks.
Ultimately, the choice between sparse and dense encoding depends on the specific application requirements, such as the need for interpretability versus semantic richness.
In OpenSearch #
Query
GET my-nlp-index/_search
"query":
"neural_sparse":
"passage_embedding":
"query_text": "Hi world",
"model_id": "aP2Q8ooBpBj3wT4HVS8a"
GET my-nlp-index/_search
"query":
"neural_sparse":
"passage_embedding":
"query_tokens":
"hi" : 4.338913,
"planets" : 2.7755864,
"planet" : 5.0969057,
"mars" : 1.7405145,
"earth" : 2.6087382,
"hello" : 3.3210192
“query_text”: “Hi world” gets expanded as “query_tokens” by additiona of more related words to increase the chances of its getting found.