sentence-transformers
tags :
Python Apps for Semantic Search #
Multilingual Sentence & Image Embedding with BERT
This framework provides an easy method to compute dense vector representations for sentences, paragraphs, and images. The models are based on transformer networks like BERT / RoBERTa / XLM-RoBERTa etc. and achieve state-of-the-art performance in various tasks. Text is embedded in vector space such that similar text are closer and can efficiently be found using cosine similarity.
Cross-Encoder #
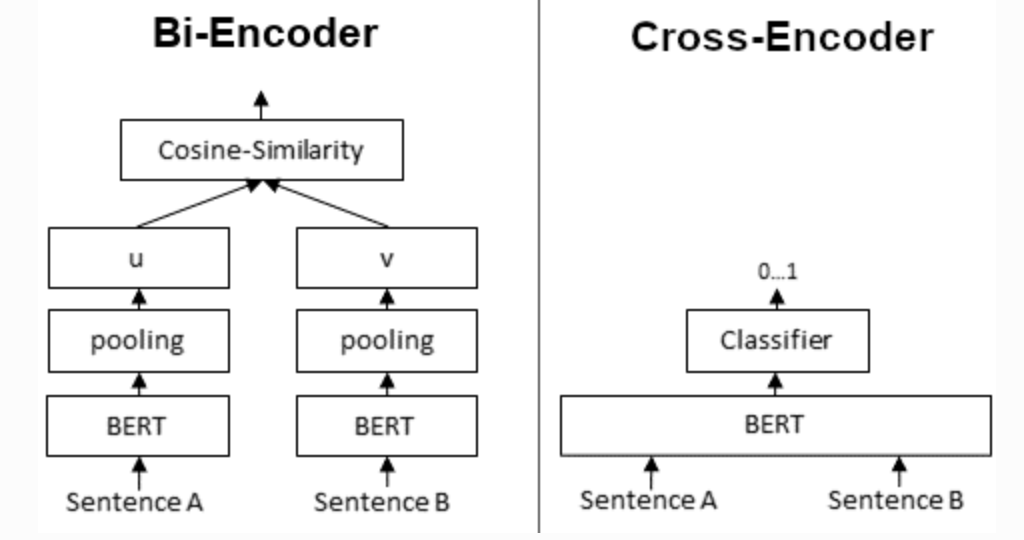 In contrast, for a Cross-Encoder, we pass both sentences simultaneously to the Transformer network. It produces than an output value between 0 and 1 indicating the similarity of the input sentence pair
In contrast, for a Cross-Encoder, we pass both sentences simultaneously to the Transformer network. It produces than an output value between 0 and 1 indicating the similarity of the input sentence pair
use-case use to evaluate the relevance of the query and its result.
Symmetric vs Assymetric Search model recommendation #
Symmetric #
both query and response are of equal length model: multi-qa-MiniLM-L6-cos-v1
Asymmetric #
query and documents are not of equal length, docs are of larger length. model: all-MiniLM-L6-v2
Multilingual Semantic Search #
distiluse-base-multilingual-cased-v1 #
Multilingual knowledge distilled version of multilingual Universal Sentence Encoder. Supports 15 languages: Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
distiluse-base-multilingual-cased-v2 #
Multilingual knowledge distilled version of multilingual Universal Sentence Encoder. This version supports 50+ languages, but performs a bit weaker than the v1 model.
paraphrase-multilingual-MiniLM-L12-v2 #
Multilingual version of paraphrase-MiniLM-L12-v2, trained on parallel data for 50+ languages.
paraphrase-multilingual-mpnet-base-v2 #
Multilingual version of paraphrase-mpnet-base-v2, trained on parallel data for 50+ languages.