paraphrase-multilingual-mpnet-base-v2
tags :
multilingual Embedding model Open Source #
Best scores for Semantic Search for multilingual use case sentence-transformers model.
Multilingual version of paraphrase-mpnet-base-v2, trained on parallel data for 50+ languages, including Arabic and English ref
Hugging Face #
OCR of Images #
2024-03-13_14-11-26_screenshot.png #

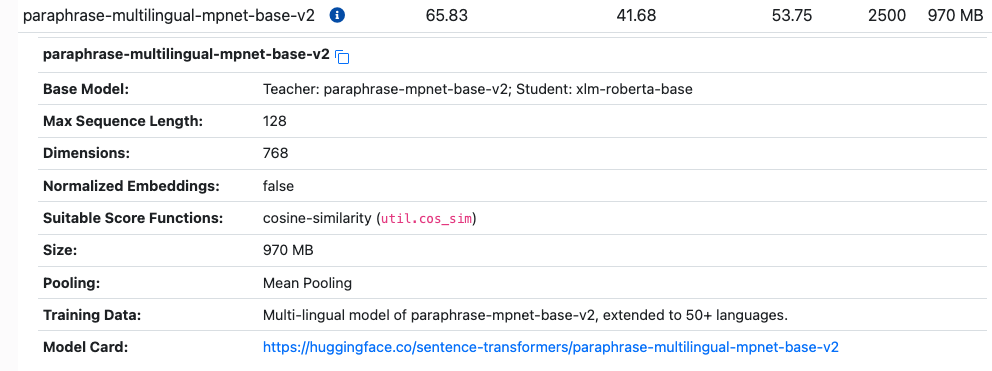
paraphrase-multlingual-mpnet-base-v2 65.83 41.68 53.75 2500 970 MB paraphrase-mutlingual-mpnet-base-v2 - Base Model: Teacher: paraphrase-mpnet-base-v2; Student: xlm-roberta-base Max Sequence Length: 128 Dimensions: 768 Normalized Embeddings: false Suitable Score Functions: cosine-similarity (util.cos_sim) Size: 970 MB Pooling: Mean Pooling Training Data: Multi-lingual model of paraphrase-mpnet-base-v2, extended to 50+ languages. Model Card: https:/huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2
OCR of Images #
2024-03-13_14-11-26_screenshot.png #
paraphrase-multlingual-mpnet-base-v2 65.83 41.68 53.75 2500 970 MB paraphrase-mutlingual-mpnet-base-v2 - Base Model: Teacher: paraphrase-mpnet-base-v2; Student: xlm-roberta-base Max Sequence Length: 128 Dimensions: 768 Normalized Embeddings: false Suitable Score Functions: cosine-similarity (util.cos_sim) Size: 970 MB Pooling: Mean Pooling Training Data: Multi-lingual model of paraphrase-mpnet-base-v2, extended to 50+ languages. Model Card: https:/huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2