opensearch-knn
tags :
OpenSearch KNN plugin #
URL Short for k-nearest neighbors, the k-NN plugin enables users to search for the k-nearest neighbors to a query point across an index of vectors. To determine the neighbors, you can specify the space (the distance function) you want to use to measure the distance between points.
Three different methods supported #
This plugin supports three different methods for obtaining the k-nearest neighbors from an index of vectors:
Approximate k-NN #
The first method takes an approximate nearest neighbor approach—it uses one of several algorithms to return the approximate k-nearest neighbors to a query vector. Usually, these Algorithm sacrifice indexing speed and search accuracy in return for performance benefits such as lower latency, smaller memory footprints and more scalable search. To learn more about the algorithms, refer to nmslib’s and faiss’s documentation.
- Approximate k-NN is the best choice for searches over large indexes (that is, hundreds of thousands of vectors or more) that require low latency.
- You should not use approximate k-NN if you want to apply a filter on the index before the k-NN search, which greatly reduces the number of vectors to be searched. In this case, you should use either the script scoring method or Painless extensions.
For more details about this method, including recommendations for which engine to use, see Approximate k-NN search.
Script Score k-NN #
The second method extends OpenSearch’s script scoring functionality to execute a brute force, exact k-NN search over “knn_vector” fields or fields that can represent binary objects. With this approach, you can run k-NN search on a subset of vectors in your index (sometimes referred to as a pre-filter search).
Use this approach for searches over smaller bodies of documents or when a pre-filter is needed. Using this approach on large indexes may lead to high latencies.
For more details about this method, see Exact k-NN with scoring script. ref
Painless extensions #
The third method adds the distance functions as painless extensions that you can use in more complex combinations. Similar to the k-NN Script Score, you can use this method to perform a brute force, exact k-NN search across an index, which also supports pre-filtering.
This approach has slightly slower query performance compared to the k-NN Script Score. If your use case requires more customization over the final score, you should use this approach over Script Score k-NN.
For more details about this method, see Painless scripting functions.
k-NN index #
The k-NN plugin introduces a custom data type, the knn_vector, that allows users to ingest their k-NN vectors into an OpenSearch index and perform different kinds of k-NN search. The knn_vector field is highly configurable and can serve many different k-NN workloads. For more information, see k-NN vector.
Lucene byte vector #
Starting with k-NN plugin version 2.9, you can use byte vectors with the lucene engine in order to reduce the amount of storage space needed. For more information, see Lucene byte vector.
Supported Methods or Engines #
In general, nmslib outperforms both faiss and Lucene on search.
However, to optimize for indexing throughput, faiss is a good option.
For relatively smaller datasets (up to a few million vectors), the Lucene engine demonstrates better latencies and recall.
- At the same time, the size of the index is smallest compared to the other engines, which allows it to use smaller AWS instances for data nodes.
Also, the Lucene engine uses a pure Java implementation and does not share any of the limitations that engines using platform-native code experience.
However, one exception to this is that the maximum dimension count for the Lucene engine is 1,024, compared with 16,000 for the other engines.
Refer to the sample mapping parameters in the following section to see where this is configured.
NMSLIB #
16,000 for the NMSLIB
"method":
"name":"hnsw",
"engine":"faiss",
"space_type": "l2",
"parameters":
"encoder":
"name":"pq",
"parameters":
"code_size": 8,
"m": 8
FAISS #
16,000 for the NMSLIB
"method":
"name":"hnsw",
"engine":"faiss",
"space_type": "l2",
"parameters":
"encoder":
"name":"pq",
"parameters":
"code_size": 8,
"m": 8
Lucene #
1,024 for the Lucene
"type": "knn_vector",
"dimension": 100,
"method":
"name":"hnsw",
"engine":"lucene",
"space_type": "l2",
"parameters":
"m":2048,
"ef_construction": 245
Distances in vector space #

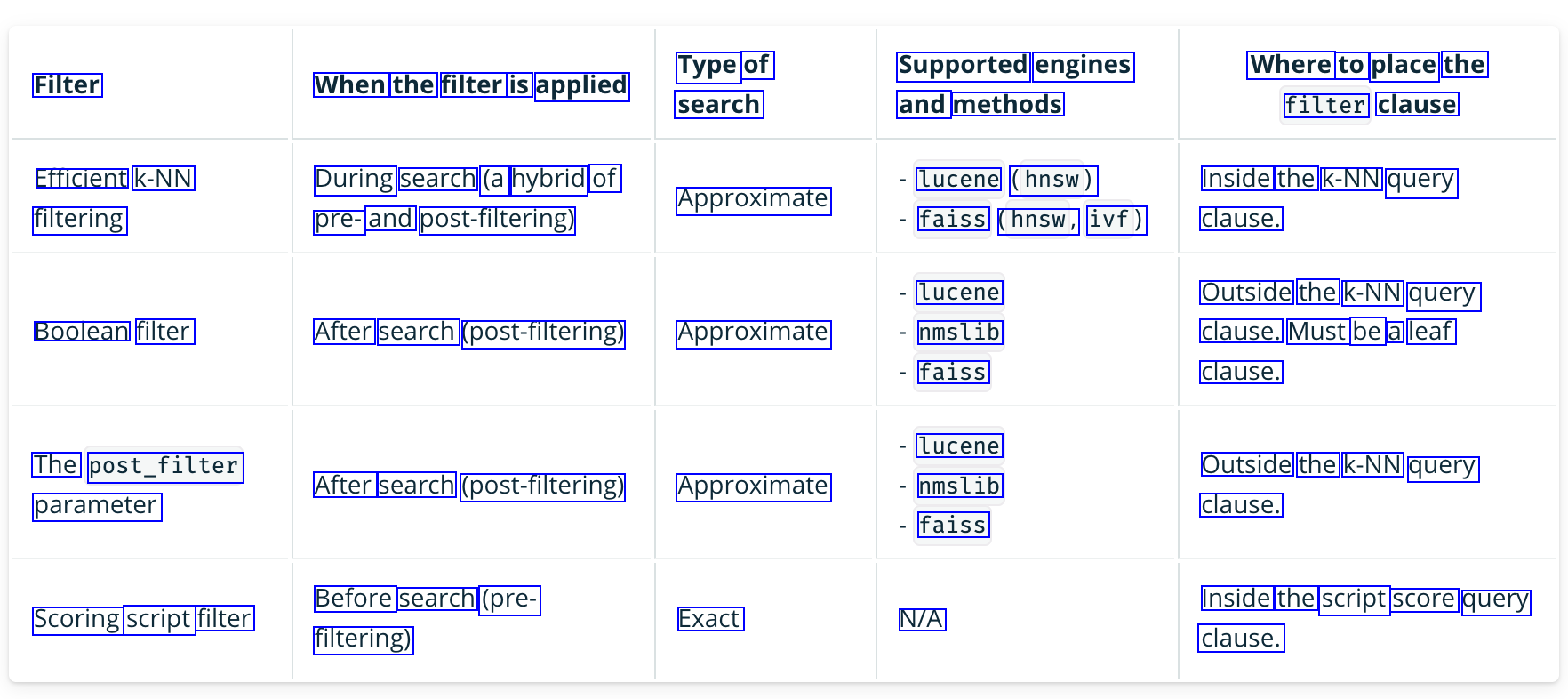
k-NN search with filters #
Efficient k-NN filtering #
This approach applies filtering during the k-NN search, as opposed to before or after the k-NN search, which ensures that k results are returned (if there are at least k results in total). This approach is supported by the following engines: Lucene engine with a Hierarchical Navigable Small World (HNSW) algorithm (k-NN plugin versions 2.4 and later) Faiss engine with an HNSW algorithm (k-NN plugin versions 2.9 and later) or IVF algorithm (k-NN plugin versions 2.10 and later)
Post-filtering #
Because it is performed after the k-NN search, this approach may return significantly fewer than k results for a restrictive filter. You can use the following two filtering strategies for this approach:
Boolean post-filter #
This approach runs an approximate nearest neighbor (ANN) search and then applies a filter to the results. The two query parts are executed independently, and then the results are combined based on the query operator (should, must, and so on) provided in the query.
The post_filter parameter #
This approach runs an ANN search on the full dataset and then applies the filter to the k-NN results.
Scoring script filter #
This approach involves pre-filtering a document set and then running an exact k-NN search on the filtered subset. It may have high latency and does not scale when filtered subsets are large.
OCR of Images #
2024-03-12_22-47-03_screenshot.png #

spaceType Distance Function (d) OpenSearch Score 1 1+ d 11 d(x,y) = Li - Vil score = n Ti - yi)? 1 1 + d 12 d(x,y) = S core - 1 1 ++ d linf d(x,y) = max(zi - yil) S core nmslib and faiss: X y X * y d(x,y) = 1 - cose l 1 - 1 1 + d S core - - Zl1 e Tili TU cosinesimil - - 7 gi Lucene: 2 - d 2 where x and Ilyll represent the norms ofvectors X and y score = respectively. Ifd N 0, S core - TU Tigi 1 innerproduct (not supported for Lucene) 1 1+ d d(x,y) = X V Ifd < 0, S core L - / a +
2024-03-12_22-50-34_screenshot.png #
Type of search Supported engines and methods Where to place the filter clause Filter When the filter is applied Efficient k-NN filtering During search (a hybrid of pre- and post-filtering) lucene (hnsw) faiss (hnsw, ivf) Inside the k-NN query Approximate clause. lucene nmslib faiss Outside the k-NN query clause. Must be a leaf Boolean filter After search (post-filtering) Approximate clause. lucene nmslib faiss The post_filter parameter Outside the k-NN query After search (post-filtering) Approximate clause. Before search (pre- filtering) Inside the script score query Scoring script filter Exact N/A clause.