multi-qa-mpnet-base-dot-v1
tags :
Open Source Embedding Model #
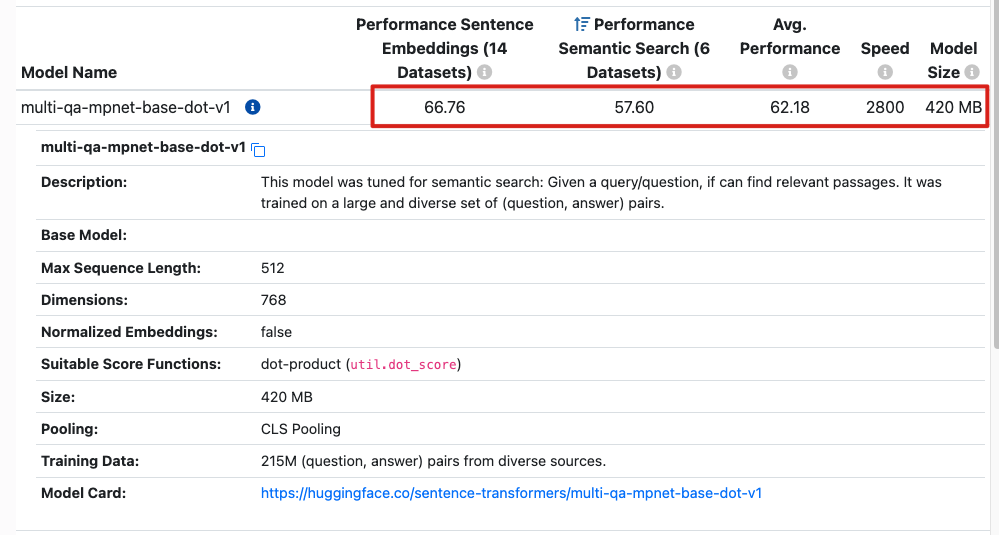
This model was tuned for Semantic Search: Given a query/question, if can find relevant passages. It was trained on a large and diverse set of (question, answer) pairs.
- Best performing sentence-transformers model for semantic search in English
Example usage #
# pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/multi-qa-mpnet-base-dot-v1')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
OCR of Images #
2024-03-13_14-03-58_screenshot.png #

Performance Sentence Embeddings (14 Datasets) i 1F Performance Avg. Semantic Search (6 Performance Speed Model Model Name Datasets) @ Size i multi-ga-mpnet-base-dot-Vi i 66.76 57.60 62.18 2800 420 MB multi-qa-mpnet-base-dot-vi Description: This model was tuned for semantic search: Given a query/question, if can find relevant passages. It was trained on a large and diverse set of (question, answer) pairs. Base Model: Max Sequence Length: Dimensions: 512 768 false Normalized Embeddings: Suitable Score Functions: dot-product (util.dot_score) Size: 420 MB Pooling: CLS Pooling Training Data: Model Card: 215M (question, answer) pairs from diverse sources. https:/huggingface.co/sentence-transformers/muli-qa-mpnet-base-dot-vi