LlamaIndex
tags :
LLM Apps #
URL github LlamaIndex (formerly GPT Index) is a data framework for LLM applications to ingest, structure, and access private or domain-specific data.
At their core, *LLMs offer a natural language(NLP) interface between humans and inferred data. Widely available models come pre-trained on huge amounts of publicly available data, from Wikipedia and mailing lists to textbooks and source code.
Applications built on top of LLMs often require augmenting these models with private or domain-specific data. Unfortunately, that data can be distributed across siloed applications and data stores. It’s behind APIs, in SQL databases, or trapped in PDFs and slide decks.
That’s where LlamaIndex comes in.
#

🦙 How can LlamaIndex help? #
LlamaIndex provides the following tools:
Data connectors #
ingest your existing data from their native source and format. These could be APIs, PDF, SQL, and (much) more.
Data indexes #
structure your data in intermediate representations that are easy and performant for LLM to consume.
Engines #
provide natural language access to your data. For example:
Query engines are powerful retrieval interfaces for knowledge-augmented output.
Chat engines are conversational interfaces for multi-message, “back and forth” interactions with your data.
Data agents #
are LLM-powered knowledge workers augmented by tools, from simple helper functions to API integrations and more.
Application integrations #
tie LlamaIndex back into the rest of your ecosystem. This could be LangChain, Flask, Docker, ChatGPT, or… anything else!
Who is LlamaIndex for? #
LlamaIndex provides tools for beginners, advanced users, and everyone in between.
Our high-level API allows beginner users to use LlamaIndex to ingest and query their data in 5 lines of code.
For more complex applications, our lower-level APIs allow advanced users to customize and extend any module —data connectors, indices, retrievers, query engines, reranking modules—to fit their needs.
Types of Indexes #
GPTVectorStoreIndex #
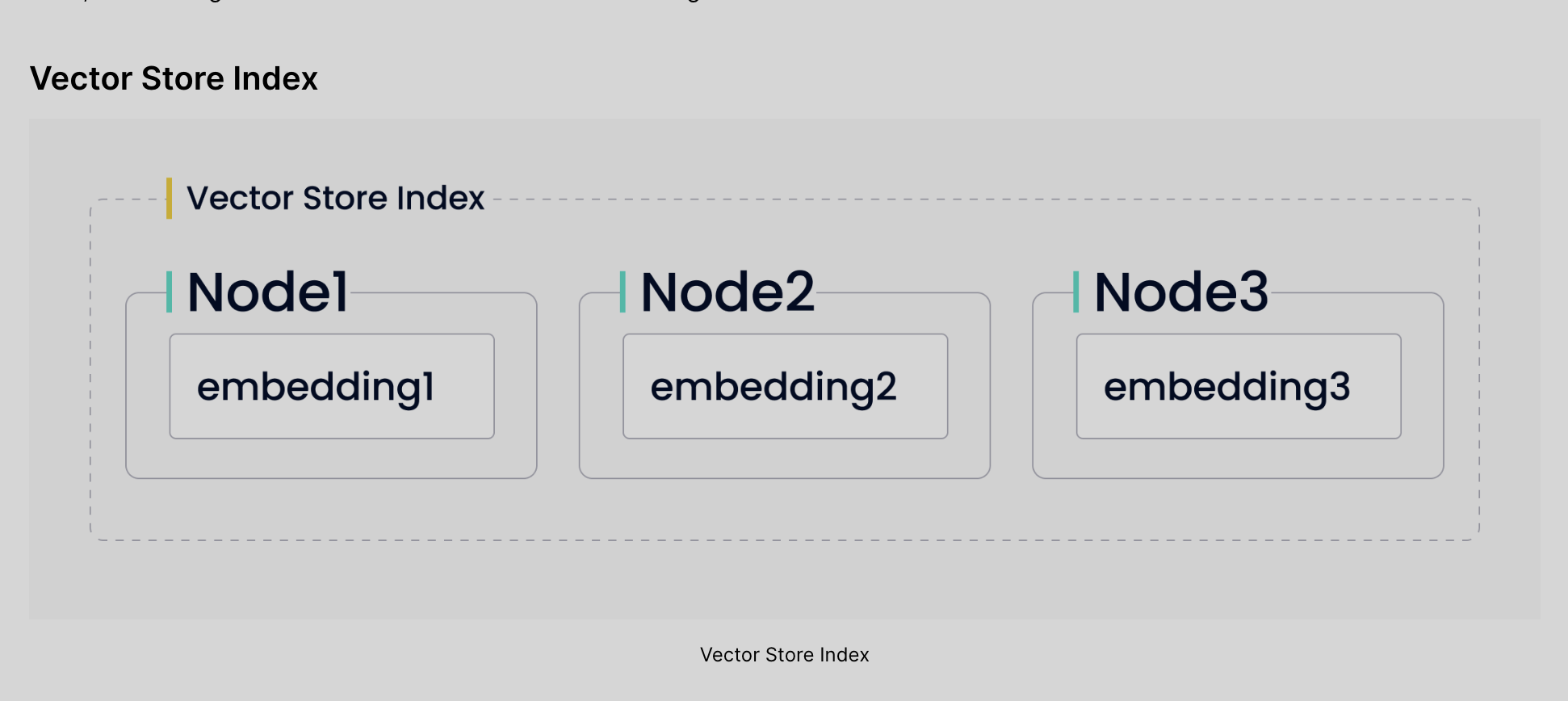
from llama_index import GPTVectorStoreIndex
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
The number of API calls during indexing depends on the amount of data. However, GPTVectorStoreIndex uses only the embeddings API which is the cheapest API provided by OpenAI.
Now, when we ask LlamaIndex to answer a question, it will create a vector from the question, retrieve relevant data, and pass the text to the LLM. The LLM will generate the answer using our question and the retrieved documents:
response = query_engine.query("...question...")
Using GPTVectorStoreIndex, we can implement the most popular method of passing private data to LLMs which is to create vectors using word embeddings and find relevant documents based on the similarity between the documents and the question.
- The GPTVectorStoreIndex implementation has an obvious advantage: It is cheap to index and retrieve the data. We can also reuse the index to answer multiple questions without sending the documents to LLM many times.
- The disadvantage is that the quality of the answers depends on the quality of the embeddings. If the embeddings are not good enough, the LLM will not be able to generate a good response. For example, I would recommend skipping the table of contents when you index the
documents.
GPTListIndex #

The GPTListIndex index is perfect when you don’t have many documents. Instead of trying to find the relevant data, the index concatenates all chunks and sends them all to the LLM. If the resulting text is too long, the index splits the text and asks LLM to refine the answer.
from llama_index.indices.list import GPTListIndex
index = GPTListIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
#
GPTListIndex may be a good choice when we have a few questions to answer using a handful of documents. It may give us the best answer because AI will get all the available data, but it is also quite expensive. We pay per token, so sending all the documents to the LLM may not be the best idea.
GPTRAKEKeywordTableIndex #
When we ask a question, first, the implementation will generate keywords from the question. Next, the index searches for the relevant documents and sends them to the LLM.
from llama_index.indices.keyword_table import GPTKeywordTableIndex
index = GPTKeywordTableIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
Every node is sent to the LLM to generate keywords. Of course, sending every document to an LLM skyrockets the cost of indexing. Not only because we pay for the tokens but also because calls to the Completion API of OpenAI take longer than their Embeddings API.
GPTKnowledgeGraphIndex #
from llama_index.indices.knowledge_graph import GPTKnowledgeGraphIndex
index = GPTKnowledgeGraphIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
The previous index was expensive and slow, but building a knowledge graph requires even more resources. GPTKnowledgeGraphIndex builds a knowledge graph with keywords and relations between them. Alternatively, we could use embeddings by specifying the retriever_mode parameter (KGRetrieverMode.EMBEDDING), but, as I mentioned earlier, I use the default values. The default behavior of GPTKnowledgeGraphIndex is based on keywords.
Example #
llama-index-which-index-should-you-use
from llama_index import GPTVectorStoreIndex
index = GPTVectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()
as_query_engine() function that creates a Retriever instance with the default values for a given index retriever.
GPTVectorStoreIndex uses only the embeddings API which is the cheapest API provided by OpenAI.
response = query_engine.query("...question...")query_engine.query("..question..")will- it will create a vector from the question,
- retrieve relevant data, and pass the text to the LLM.
- The LLM will generate the answer using our question and the retrieved documents:
Plugins #
Projects using llama-index #
Llama Lab is a repo dedicated to building cutting-edge projects using LlamaIndex, github.
Vocabulary #
Index #
are like database
Document #
piece of unstructured, semi-structured or json, data stored in an Index. Like a row in a table.
Nodes #
Chunks of documents loaded from the storage.
Case Studies #
Semantic Search with LlamaIndex #
Semantic search is a powerful application that can be built using LlamaIndex. Leveraging its indexing capabilities allows developers to generate efficient and accurate search results that take into account the intent and contextual meaning of a search query. LlamaIndex’s optimization for indexing and retrieval leads to increased speed and accuracy in semantic search applications.
Employing LlamaIndex for semantic search applications offers several benefits, including:
- tailoring the search experience to ensure users receive the most relevant results
- optimizing indexing performance by adhering to best practices
- refining LangChain components to improve search accuracy
- creating powerful semantic search applications that provide precise insights and actionable information