LangChain
tags :
Python Apps, Framework, LLM Apps #
github Building applications with LLM (ChatGPT) through composability
Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. However, using these LLMs in isolation is often insufficient for creating a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.
JAK observation #
guiding the AI to get the job done, with chains and agents.
6 main areas #
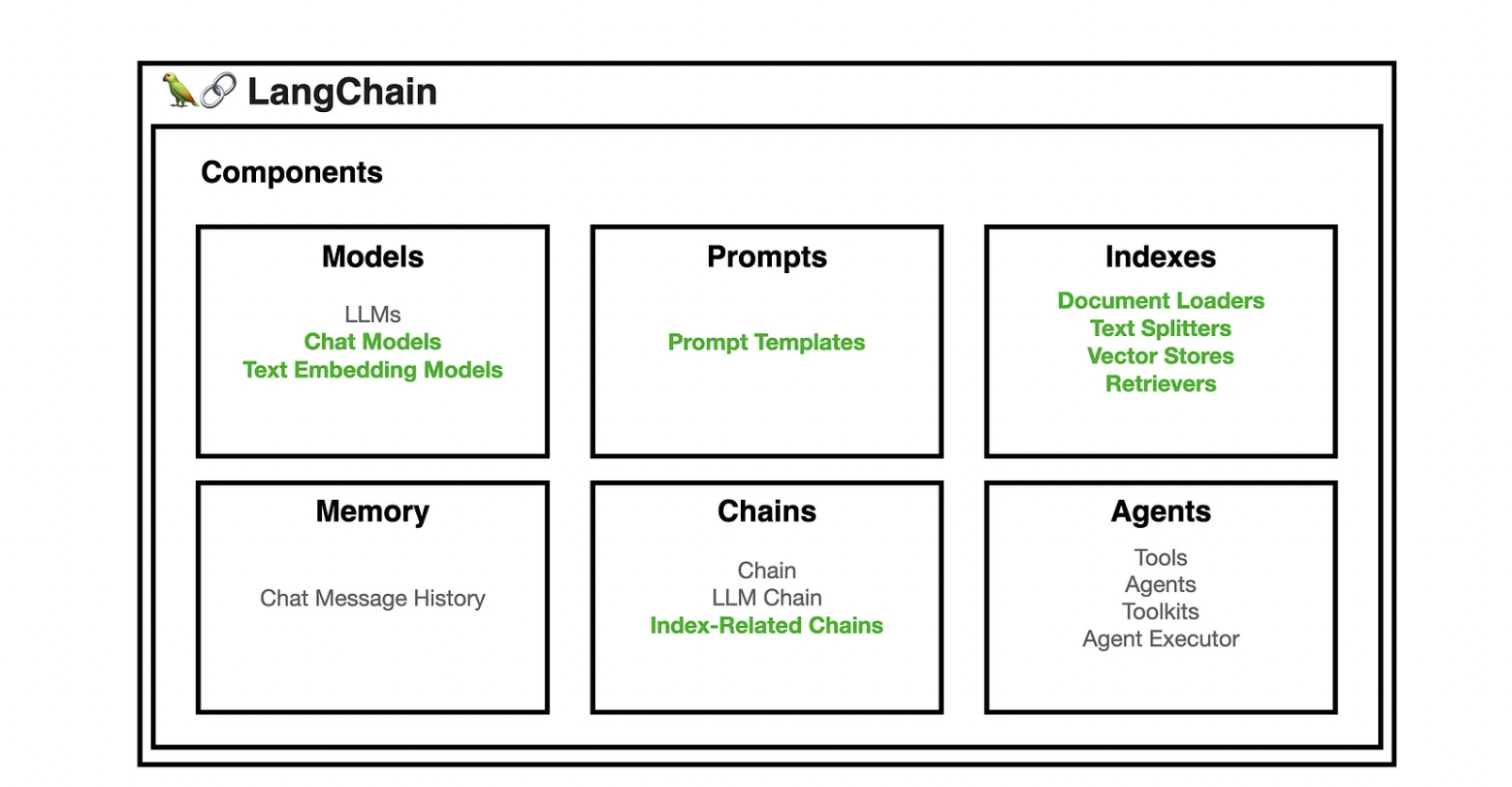
There are six main areas that LangChain is designed to help with. These are, in increasing order of complexity:
LLMs and Prompts: #
This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
Chains #
Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
Data Augmented Generation #
Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step.
Examples #
- Summarization of long pieces of text and
- question/answering over specific data sources.
Agents #
Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
Creating a custom agent #
Memory #
Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
Evaluation #
[BETA] Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
Data Connection #
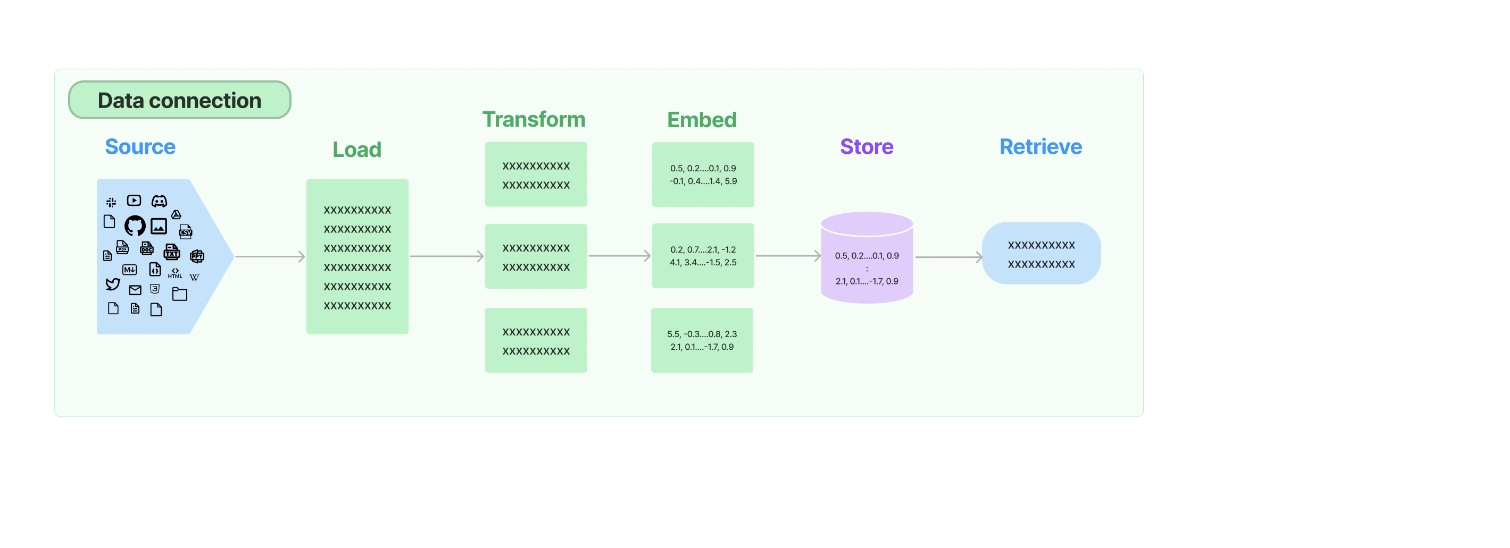
Querying a custom datasource #
Ingesting or Embedding #
Querying with LLM #
Projects using LangChain with LLM #
privateGPT #
langchain-falcon-chainlit #
https://github.com/sudarshan-koirala/langchain-falcon-chainlit Simple Chat UI using Falcon model, LangChain and Chainlit
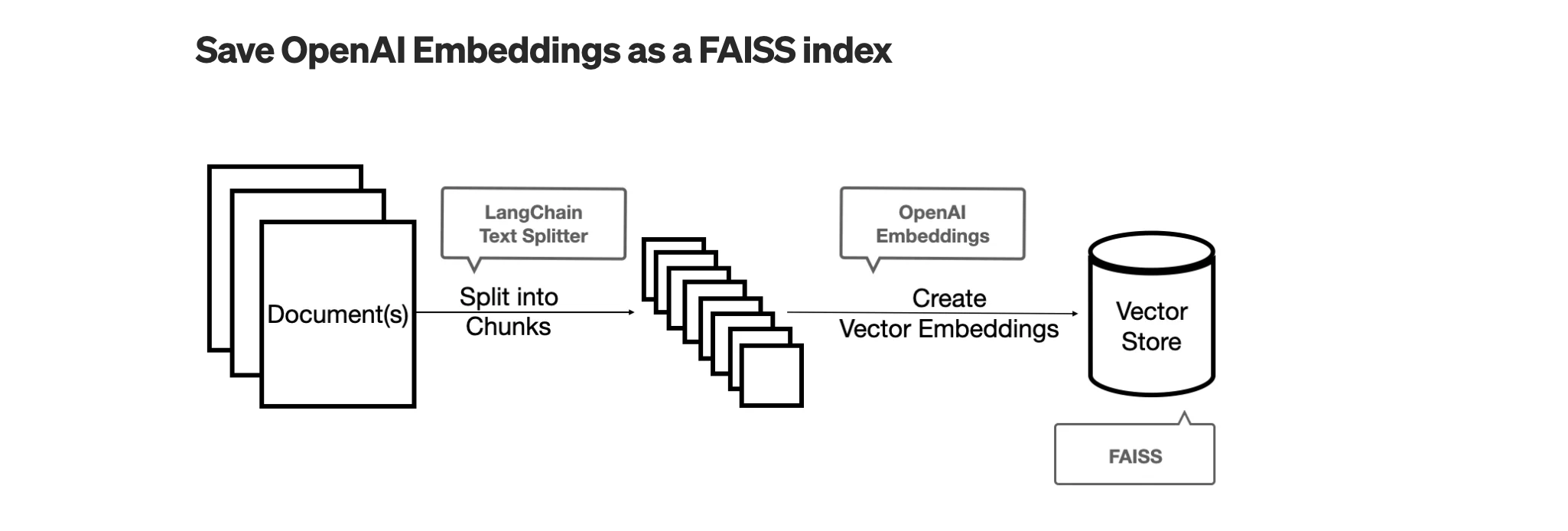
Vector Database #
Embedding #
Using sentence-transformers for embedding #
# !pip install sentence_transformers > /dev/null
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# Equivalent to SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text, "This is not a test document."])
## or
from langchain.embeddings import SentenceTransformerEmbeddings
embeddings = SentenceTransformerEmbeddings(model="all-MiniLM-L6-v2")
LlamaIndex vs LangChain #
- If the goal is mainly an intelligent search tool llamaindex is great, if you want to build a chatgpt clone capable of creating plugins that is a whole different thing.
- Langchain allows you to leverage multiple instance of ChatGPT, provide them with memory, even multiple instance of llamaindex.
- Things you can do with langchain is build agents, that can do more than one things, one example is execute Python code, while also searching google.
- Basically llmaindex is a smart storage mechanism, while Langchain is a tool to bring multiple tools together.
- LlamaIndex focuses on efficient indexing and retrieval, while LangChain offers a more general purpose Framework
- Queryring data before getting to the prompt, LlamaIndex is better
Document #
Pass page_content in as positional or named arg.
example
from langchain.schema import BaseRetriever, Document
document = Document(
page_content="Hello, world!",
metadata="source": "https://example.com",
id="some-id" # optional, unique identitifer
)
param id: Optional[str] = None #
An optional identifier for the document.
Ideally this should be unique across the document collection and formatted as a UUID, but this will not be enforced.
New in version 0.2.11.
param metadata: dict [Optional] #
Arbitrary metadata associated with the content.
param page_content: str [Required] #
String text.