KNN
tags :
K-Nearest Neighbors #
ref ref 2 The K-Nearest Neighbors (KNN) algorithm is a robust and intuitive method employed to tackle classification and regression problems. By capitalizing on the concept of similarity, KNN predicts the label or value of a new data point by considering its K closest neighbours in the training dataset.
What is the K-Nearest Neighbors Algorithm? #
K-Nearest Neighbours is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining, and intrusion detection.
It is widely disposable in real-life scenarios since it is non-parametric, meaning, it does not make any underlying assumptions about the distribution of data (as opposed to other algorithms such as GMM, which assume a Gaussian distribution of the given data)*. We are given some prior data (also called training data), which classifies coordinates into groups identified by an attribute.
As an example, consider the following table of data points containing two features:
Distance Metrics Used in KNN Algorithm #
As we know that the KNN algorithm helps us identify the nearest points or the groups for a query point. But to determine the closest groups or the nearest points for a query point we need some metric. For this purpose, we use below distance metrics:
Euclidean Distance #
This is nothing but the cartesian distance between the two points which are in the plane/hyperplane. Euclidean distance can also be visualized as the length of the straight line that joins the two points which are into consideration. This metric helps us calculate the net displacement done between the two states of an object.
\text{distance}(x, X_i) = \sqrt{∑j=1d (x_j - Xi_j)^2} ]
Manhattan Distance #
Manhattan Distance metric is generally used when we are interested in the total distance traveled by the object instead of the displacement. This metric is calculated by summing the absolute difference between the coordinates of the points in n-dimensions.
d\left ( x,y \right )={∑i=1n\left | x_i-y_i \right |}
Minkowski Distance #
We can say that the Euclidean, as well as the Manhattan distance, are special cases of the Minkowski distance.
d\left ( x,y \right )=\left ( {∑i=1n\left ( x_i-y_i \right )^p} \right )\frac{1}{p}
From the formula above we can say that when p = 2 then it is the same as the formula for the Euclidean distance and when p = 1 then we obtain the formula for the Manhattan distance.
OpenSearch 2.8 #
Also, the Lucene engine uses a pure Java implementation and does not share any of the limitations that engines using platform-native code experience. However, one exception to this is that the maximum dimension count for the Lucene engine is 1,024, compared with 16,000 for the other engines. Refer to the sample mapping parameters in the following section to see where this is configured.
#
knn_vector data type #
hnsw #
- Hierarchical proximity graph approach to Approximate k-NN search. For more details on the , see this abstract.
- supported spaces:
- I2
- cosinesimil
HNSW PARAMETERS #
ef_construction #
- The size of the dynamic list used during k-NN graph creation.
- Higher values lead to a more accurate graph but slower indexing speed.

m #
- The number of bidirectional links that the plugin creates for each new element.
- Increasing and decreasing this value can have a large impact on memory consumption.
- Keep this value between 2 and 100.
Supported engine and search method in opensearch 2.8 #
shared this information to me by, arun.prakash.n.m@oracle.com,
- Hierarchical Navigable Small Worlds (HNSW) and Inverted File Index (IVF)
{
"type": "knn_vector",
"dimension": 100,
"method": {
"name":"hnsw",
"engine":"lucene",
"space_type": "l2",
"parameters":{
"m":512, # 2048 will not work
"ef_construction": 245
}
}
}
INDEX_NAME = "arxiv-cosine"
body = {
"settings": {"index": {"knn": "true", "knn.algo_param.ef_search": 100}},
"mappings": {
"properties": {
VECTOR_NAME: {
"type": "knn_vector",
"dimension": VECTOR_SIZE,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "nmslib",
"parameters": {"ef_construction": 128, "m": 24},
},
},
}
},
}
response = client.indices.create(INDEX_NAME, body=body)
definitions of params
however using “m” as 2048 was causing this error: This parameter is related to the maximum number of connections allowed, and in your case, it’s set to 2048, which is higher than the maximum allowed value of 512. This error typically occurs in the settings of the KNN plugin for OpenSearch. changing it 512 worked.
faiss/nmslib engine is not supported yet, #
according to the oracle support
Hi Team,
We are from the OpenSearch engineering team, and we have noticed that you have create a knn model with faiss engine.faiss/nmslib engine is not supported yet. Cluster is currently red. Please delete the indices associated with the faiss engine
Embeddings vector generation #
If you are not using an ad hoc library or API to generate your embeddings vectors (e.g., OpenAI Embeddings API or Cohere), both OpenSearch and Elasticsearch will provide you with an ingest pipeline processor that will help you do it on the fly. Those ingest processors are called `text_embedding` in OpenSearch and `inference` in Elasticsearch, and both can be set up in a similar way. On the downside, the Elasticsearch `inference` processor is not available with the Free license.
#
OCR of Images #
2023-12-11_13-46-43_screenshot.png #
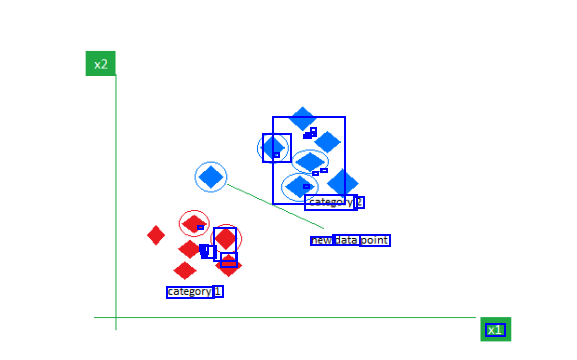
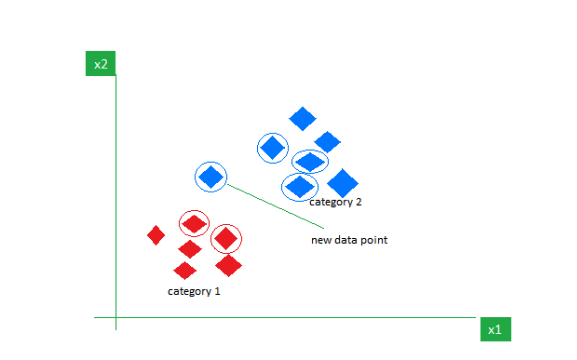
- - - - - - - C - - - category: 2 a A - - - - - - - new data point category 1 x1
2024-01-04_18-17-52_screenshot.png #
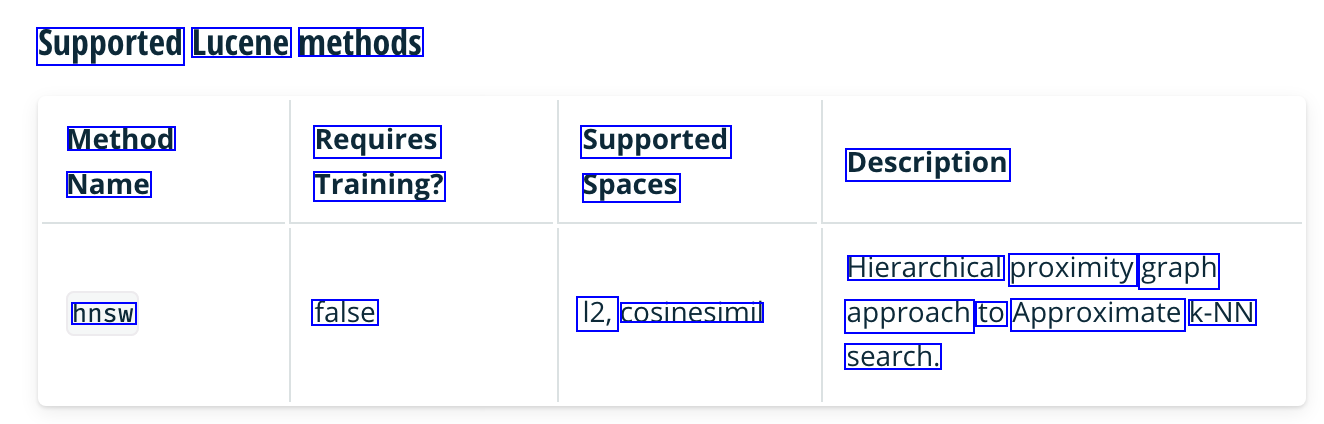
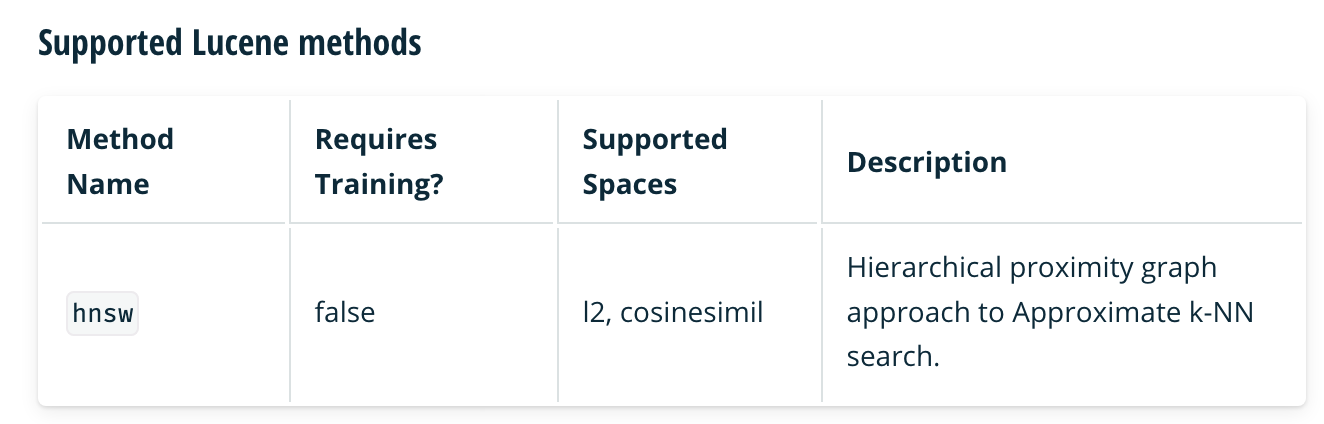
Supported Lucene methods Method Requires Supported Description Name Training? Spaces Hierarchical proximity graph hnsw false 12, cosinesimil approach to Approximate k-NN search.
2024-01-04_18-02-01_screenshot.png #

Parameter Name Required Default Updatable Description The size of the dynamic list used during k- NN graph creation. Higher values ef construction false 512 false lead to a more accurate graph but slower indexing speed.
2024-01-04_18-03-01_screenshot.png #

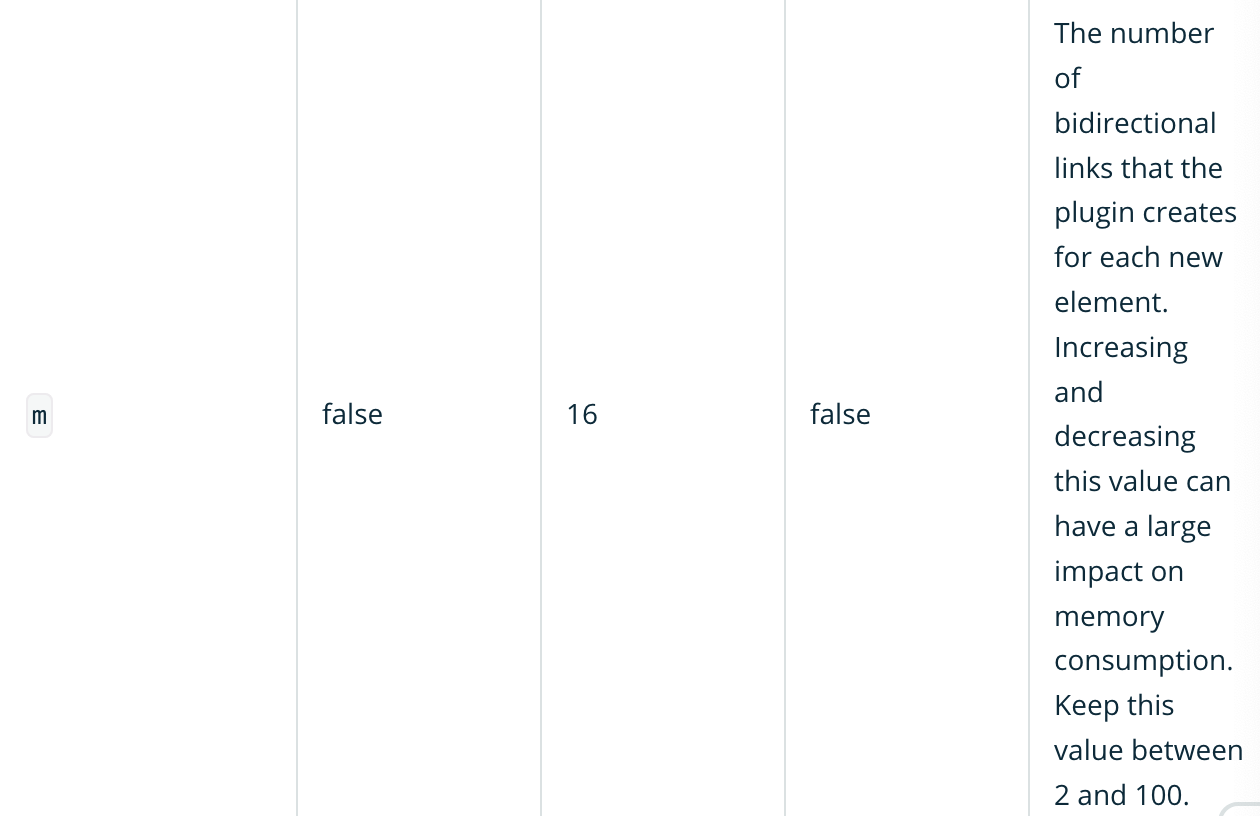
The number of bidirectional links that the plugin creates for each new element. Increasing and m false 16 false decreasing this value can have a large impact on memory consumption. Keep this value between 2 and 100.
OCR of Images #
2023-12-11_13-46-43_screenshot.png #
- - - - - - - C - - - category: 2 a A - - - - - - - new data point category 1 x1
2024-01-04_18-17-52_screenshot.png #
Supported Lucene methods Method Requires Supported Description Name Training? Spaces Hierarchical proximity graph hnsw false 12, cosinesimil approach to Approximate k-NN search.
2024-01-04_18-02-01_screenshot.png #
Parameter Name Required Default Updatable Description The size of the dynamic list used during k- NN graph creation. Higher values ef construction false 512 false lead to a more accurate graph but slower indexing speed.
2024-01-04_18-03-01_screenshot.png #
The number of bidirectional links that the plugin creates for each new element. Increasing and m false 16 false decreasing this value can have a large impact on memory consumption. Keep this value between 2 and 100.
OCR of Images #
2023-12-11_13-46-43_screenshot.png #
- - - - - - - C - - - category: 2 a A - - - - - - - new data point category 1 x1
2024-01-04_18-17-52_screenshot.png #
Supported Lucene methods Method Requires Supported Description Name Training? Spaces Hierarchical proximity graph hnsw false 12, cosinesimil approach to Approximate k-NN search.
2024-01-04_18-02-01_screenshot.png #
Parameter Name Required Default Updatable Description The size of the dynamic list used during k- NN graph creation. Higher values ef construction false 512 false lead to a more accurate graph but slower indexing speed.
2024-01-04_18-03-01_screenshot.png #
The number of bidirectional links that the plugin creates for each new element. Increasing and m false 16 false decreasing this value can have a large impact on memory consumption. Keep this value between 2 and 100.