Chunking for creating Embeddings
Embedding #
Relevant Suggestions #
Inject context in content #
It’s better, but try to give some context about the metadata that you’re using. Something like: text = f’Document title: df[“title”]. Document subtitle: df[“subtitle”]. Chunk content: df[“content”].’ ref
Default characters #
Quick rule of thumb: 4000 characters. Real solution: it fully depends on your use case, your documents and the questions that your app faces. I’m usually happy with the results that I get with a two-steps semantic search, that I explained in this link 389. Hope it helps! community openai
Preprocessing #
About the pre-processing: that’s an extremely interesting question. In my experience, a proper preprocessing enhances the semantic search results dramatically. There are tons of suitable strategies here. For me, augmenting the context of each chunk with off-chunk info works really well. For instance: including metadata about the chunk (title of the document where the chunk comes from, author, keywords extracted via NER, short chunk/document summary, etc.) I explained this idea here: The length of the embedding contents - #7 by AgusPG 288 ref openai community
Global and Local context #
Layout parsing #
llmsherpa #
LayoutPDFReader parses layouts

LlamaIndex #
 semantic chunking in llama-index
semantic chunking in llama-index
llama-parse #
github Parse files for optimal RAG
Smart Chunking or Layout based chunking #
blog where author explains why this is better than naive chunking
5 Levels of Text splitting #
jupyter notebook explaining it
Semantic Chunking (4th level) #
youtube Greg Kamradt
OCR of Images #
2024-02-25_16-24-17_screenshot.png #

Chunk 1 3 Fine-tuning BART 3 Fine-tuning BART Chunk 1 Expanded (Alternative) The representations produced by BART can be used in several ways for downstream applications. The representations produced by BART can be used in several ways for downstream applications. 3.1 Sequence Classification Tasks For sequence classification tasks, the same inputi is fed into the encoder and decoder, and the linal hidden state of the final decoder loken is fed into new multi- class lincar classifier This approach is relnted to the CLS loken in BERT: however we add the additional taken to the end 50 that representation for the token in the decoder can: attcud to decoder states from the complete input (Figure 3a). 3.2 Token Classification Tasks For token classification tasks, such as answer endpoint classification for SQUAD, we foed the complete doc- ument into the encoder and decuder, and use the tup hidden state of the decoder: as a representation for cach wurd. This representation is used to classify the taken. 33 Sequence Generation Tasks Bocause. BARTI has an autoregressive decoder, it can be directly fine tuned for sequence generntion tasks such as abstractive question answering and summarization. In both of these tasks, information is copied from the 3 Fine-tuning BART The: representations produced by BART can be ased in several ways for downstream applications. 3.1 Sequence Classitication Tasks For soquence classification tasks, the same input is fed into the encoder: and decoder, and the final hidden state of the final decoder token is fed into new multi-class linear classilier. This approach is related lo the CLS token in BERT; however we add the additional token lo the end s0 thal representation fur the luken in the decoder can attend to decoder states from the complete input (Figure 3a). 3.2 Token Classilication lasks For token classilication tasks, such as answer endpoint classification for SQUAD, we feed the complete doc- ument into the encoder and decoder, and use the top hidden state of the decoder as a representation for each word. This cprcsemtation is used to classify the token. 3.3 Sequence Generation Tasks Bocanse. BARTI has an autoregressive decoder, it can be directly fine tuned for sequence generation tasks such as abstractive question answering and summarization. In both of these tasks, information is copied from the 3 Fine-tuning BART 3.1 Sequence Classification' Tasks For: sequence classification tnsks, the same input is fed into the encoder and decoder, and the linal hidden stale of the final decoder token is fed into new multi-class lincar classifier. This approach is related to the CLS token in BERT; hewever we add the additional toiken to the end s0 thar representation for the token in the decoder can allend lo docoder stales from the complete input (Figure Ba). 3 line-tuning BART 3.2 Token Classilication Tasks For loken classilication Lasks, such as answer endpoint classification fur SQUAD, we feed the camplete doc oment into the encoder. and decoder, and use the top hidden sstate af the decoder as representation for each word. This representation is used to classify the token. 3 Fine-tuning BART 3.3 Sequence Generation' Tasks Because BART has an autoregressive decoder, it canl be directly fine tuned for sequence generation tasks such as abstractive question answering and summarization. In both of these tasks, information is copied from the Chunk 2 Chunk 3 Chunk 4
2024-02-25_16-24-33_screenshot.png #
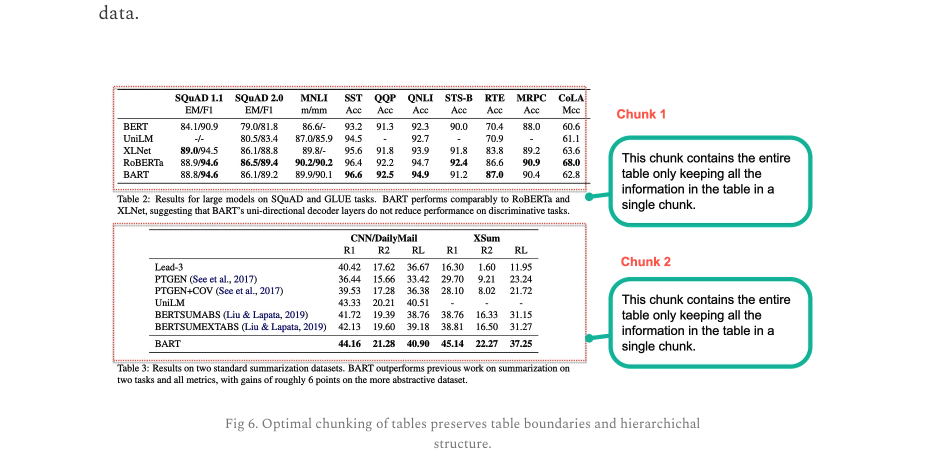
data. SQUAD 1.1 SQUAD 2.0 MNLI SST QQP QNLI STS-B RTE MRPC CoLA EM/F1 EM/FI m/mm Acc Acc Acc Acc Acc Acc Mcc BERT 84.1/90.9 79.0/81.8 86.6/- 93.2 91.3 92.3 90.0 70.4 88.0 60.6 XLNet 89.0/94.5 86.1/88.8 89.8/- 95.6 91.8 93.9 91.8 83.8 89.2 63.6 ROBERIa 88.9/94.6 86.5/89.4 90.2/90.2 96.4 92.2 94.7 92.4 86.6 90.9 68.0 BART 88.8/94.6 86.1/89.2 89.9/90.1 96.6 92.5 94.9 91.2 87.0 90.4 62.8 Table 2: Results for large models on SQUAD and GLUE tasks. BART performs comparably to RoBERTa and XLNet, suggesting that BART's uni-directional decoder layers do not reduce performance on discriminative tasks. Chunk 1 UniLM - 80.5/83.4 87.0/85.9 94.5 92.7 70.9 61.1 This chunk contains the entire table only keeping all the information in the table in a chunk. single CNN/DailyMail R1 R2 RL R1 R2 RL 40.42 17.62 36.67 16.30 1.60 11.95 36.44 15.66 33.42 29.70 9.21 23.24 39.53 17.28 36.38 28.10 8.02 21.72 43.33 20.21 40.51 XSum Lead-3 PTGEN (See et al., 2017) PTGEN+COV (See et al., 2017) UniLM Chunk 2 This chunk contains the entire table only keeping all the information in the table in a single chunk. BERISUMABS (Liu & Lapata, 2019) 41.72 19.39 38.76 38.76 16.33 31.15 BERISUMEXTABS (Liu & Lapata, 2019) 42.13 19.60 39.18 38.81 16.50 31.27 BART 44.16 21.28 40.90 45.14 22.27 37.25 Table 3: Results on wo standard summarization datasets. BART outperforms previous work on summarization on two tasks and: all metrics, with gains of roughly 6 points on the more abstractive dataset. Fig 6. Optimal chunking of tables preserves table poundaries and hierarchichal structure.
2024-02-25_16-30-13_screenshot.png #
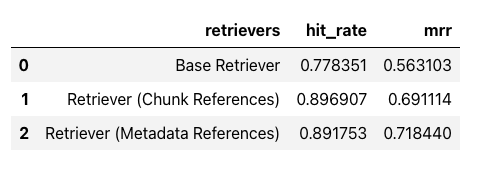
retrievers hit_ rate mrr Base Retriever 0.778351 0.563103 1 Retriever (Chunk References) 0.896907 0.691114 2 Retriever (Metadata References) 0.891753 0.718440