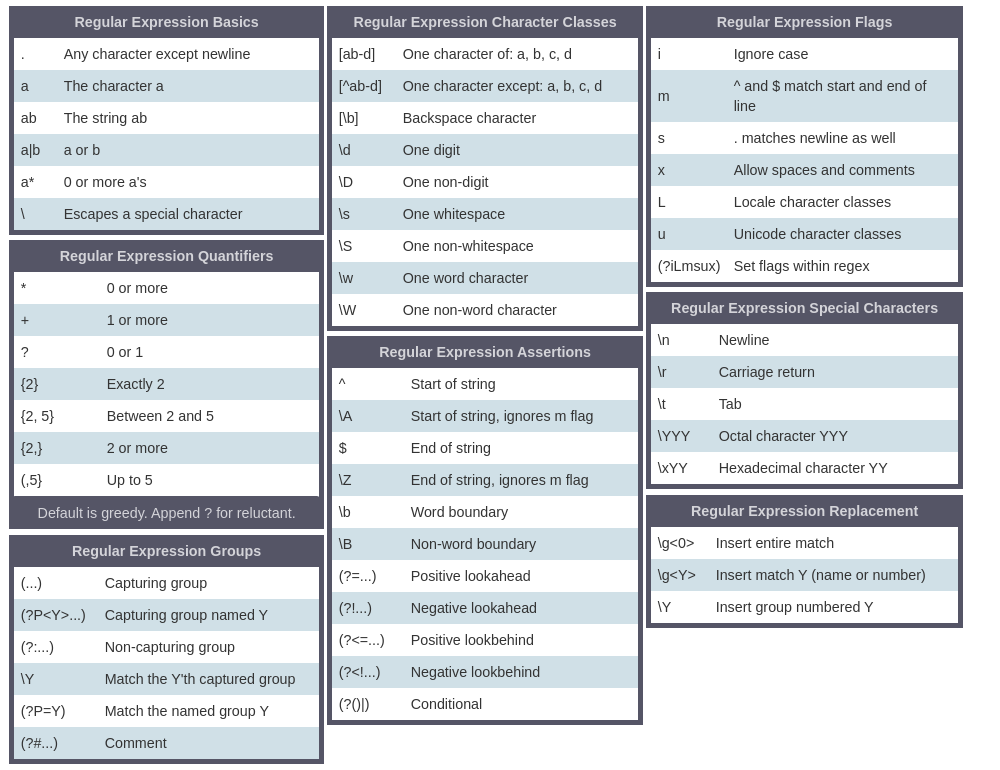
Regular Expressions
re CS #
Look-arounds #
- Lookahead and lookbehind, collectively called “lookaround”
- Lookarounds are zero width assertions.
- They check for a regex (towards right or left of the current position - based on ahead or behind), succeeds or fails when a match is found (based on if it is positive or negative) and discards the matched portion.
- metaphor of ahead and behind is used wrt to left to right direction
(?): are always present!: means negative=: means positive<: look behind (direction)
Look-ahead #
(?=): positiveA(?=B): Find expression A where expression B follows:
- ~(?!): negative ~A(?!B): Find expression A where expression B does not follow:
Look-behind #
(?<=): positive(?<=B)A: Find expression A where expression B precedes:(?<!): negative
(?<!B)A: Find expression A where expression B does not precede
Example #
bar(?=bar) finds the 1st bar ("bar" which has "bar" after it)
bar(?!bar) finds the 2nd bar ("bar" which does not have "bar" after it)
(?<=foo)bar finds the 1st bar ("bar" which has "foo" before it)
(?<!foo)bar finds the 2nd bar ("bar" which does not have "foo" before it)
Refs #
Image #
 \w (word character) matches any single letter, number or underscore (same as [a-zA-Z0-9_])*.
\w (word character) matches any single letter, number or underscore (same as [a-zA-Z0-9_])*.
Python suspendedfc #
| position | ease | box | interval | due |
|---|---|---|---|---|
| front | 2.5 | 0 | 0 | 2021-05-11T07:42:36Z |
Match object #
- A Match Object is an object containing information about the search and the result.
- This object is returned by `re.search()`, `re.match()`, `re.findall()`.
- Has propterties and methods
`.span()` returns a tuple containing the start-, and end positions of the match.
`.string` returns the string passed into the function
`.group()` returns the part of the string where there was a match
import re txt = "My name is Javeed Ali Khan" result = re.search(r"(\bJ\w+) (\bA[li]{2})", txt) print(result.span()) print(result.group()) # all match print(result.group(0)) # all match print(result.group(1)) # 1st group print(result.group(2)) # 2nd group print(result.string)(11, 21) Javeed Ali Javeed Ali Javeed Ali My name is Javeed Ali Khan
re methods 1 #
| re.compile(pattern, flags) | Compile a regular expression of pattern, with flag s |
|---|---|
| re.match(pattern, string) | Match pattern only at beginning of string |
| re.search(pattern,string) | Match patterns anywhere in the string |
| re.split(pattern, string) | Split string by occurences of pattern |
| re.sub(pttrn_2_repl, repl_with, in_string) |
re method Objects 1 #
| match.group(“name”) | Return subgroup “name” of match |
|---|---|
| match.groups() | Return tuple containing all subgroups of match |
| match.groupdict() | Return dict containing all named subgroups of match |
| match.start(group) | Return start index of substring match by group |
| match.end(group) | Return end index of substring matched by group |
| match.span(group) | Return 2-tuple start and end indices of group in match |
re methods 2 #
| re.fullmatch(pattern, string) | Match pattern if whole string matches regular expression |
|---|---|
| re.findall(pattern, string) | Return all non-overlapping matches of pattern in string, as a list of strings |
| re.finditer(pattern, string) | Return an iterator yielding match objects over non-overlapping matches of pattern in string |
| re.subn(pattern, str2, string) | Replace left most occurrences of pattern in string with str2, but return a tuple of (newstring, # subs made) |
| re.purge() | Clear the regular expression cache |
Difference between match , search and findall #
| match | search | findall |
|---|---|---|
| 1. first occurence | 1. first occurence | returns all occurences |
| 2. if match found in another line returns null | 2. check all lines unline match | returns list of strings |
| 3. returns match object | 3. returns match object | or list of tuples of strings not match object |
findall example
``` cc_list = ‘‘‘Ezra Koenig <ekoenig@vpwk.com>, Rostam Batmanglij <rostam@vpwk.com>, Chris Tomson <ctomson@vpwk. Bobbi Baio <bbaio@vpwk.com’’’ >>> matched = re.findall(r’\w+\@\w+\.\w+’, cc_list) >>> matched [’ekoenig@vpwk.com’, ‘rostam@vpwk.com’, ‘ctomson@vpwk.com’, ‘cbaio@vpwk.com’] >>> matched = re.findall(r’(\w+)\@(\w+)\.(\w+)’, cc_list) >>> matched [(’ekoenig’, ‘vpwk’, ‘com’), (‘rostam’, ‘vpwk’, ‘com’), (‘ctomson’, ‘vpwk’, ‘com’), (‘cbaio’, ‘vpwk’, ‘com’)] >>> names = [x[0] for x in matched] >>> names [’ekoenig’, ‘rostam’, ‘ctomson’, ‘cbaio’] ```
Examples #
Named group #
```(?P<name>regex)```
print("start")
import re
txt = """Javeed Ali Khan Mohammed 2284440597 lisai Taaina Immune by first dose Last update: Tuesday 8 June, 09:42 PM Immune by first dose until 22/10/2021 New Services Display All > COVID-19 Vaccine Certify Mobile Organ Health Donation Passport Number D00 000 of Javeed Ali Khan Mohammed 2284440597 lisai Taaina Immune by first dose """
txt = """Immune by first dose Last update Mon, 14 Jun 12:00 PM O Current Permits Immune by first dose Last update Mon, 14 Jun 12:00 PM O Current Permits"""
# pattern = r"""(?P<day_of_week>(mon|tues|wed(nes)?|thur(s)?|fri|sat(ur)?|sun)(day)?)(?<day_of_month>\s*\d+)(?<month>\s*(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?),\s*)(?p<time>1[0-2]|0?[1-9]):([0-5][0-9]) ?([AaPp][Mm])"""
pattern = r"""(?P<day_of_week>(mon|tues|wed(nes)?|thur(s)?|fri|sat(ur)?|sun)(day)?,?)(?P<day_of_month>\s*\d+)(?P<month>\s*(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?),?\s*)(?P<time>(1[0-2]|0?[1-9]):([0-5][0-9]) ?([AaPp][Mm]))"""
# pattern = r"""((mon|tues|wed(nes)?|thur(s)?|fri|sat(ur)?|sun)(day)?)(\s*\d+)(\s*(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|(Nov|Dec)(?:ember)?),\s*)(1[0-2]|0?[1-9]):([0-5][0-9]) ?([AaPp][Mm])"""
result = re.search(pattern, txt, re.IGNORECASE)
print("result is")
print(result)
if result:
print(result.group("day_of_week"))
print(result.group("day_of_month"))
print(result.group("month"))
print(result.group("time"))
start
result is
<re.Match object; span=(33, 53), match='Mon, 14 Jun 12:00 PM'>
Mon,
14
Jun
12:00 PM
Emacs #
Native regular expression support #
- Grouping is performed with backslashes followed by parentheses ‘\(’, ‘\)’
- " “: space not “\s\”
- look-ahead and look-behind are not supported
- supported constructs
“visual-regexp-steroids” package #
github depends on visual-regexp
Example #
to replace all “sample.html” to “sample” ([a-z0-9]*)\.html -> \1 # “\1” captures the group “([a-z0-9]*)”